python爬取电影并下载
本文共 3450 字,大约阅读时间需要 11 分钟。
一、概述
对于一个宅男,喜欢看电影,每次打开电影网站,各种弹出的广告,很是麻烦,还是要自己去复制下载链接到迅雷上粘贴并下载,这个过程中还有选择困难症;这一系列的动作让人甚是不爽,不如有下好的,点着看就好了;作为一个python爱好者,结合对爬虫的一点小了解,于是周末花了点时间用python写了一个爬取某电影网站上的最新电影板块;
思路:爬虫针对某电影网站,收集电影名,下载链接,评分,等信息;当天更新的电影,特别的打印出来;同时通过评分调用迅雷下载,当然先判断下,是否已经下载过了,再决定是否下载;然后,就是可以看了~本次版本是基于python3.x下通过,在windows上才能调用迅雷~linux平台只能获取相关信息!
python安装和相关的模块安装这里不讲述,如有不明白请留言我~jupyter上运行如下: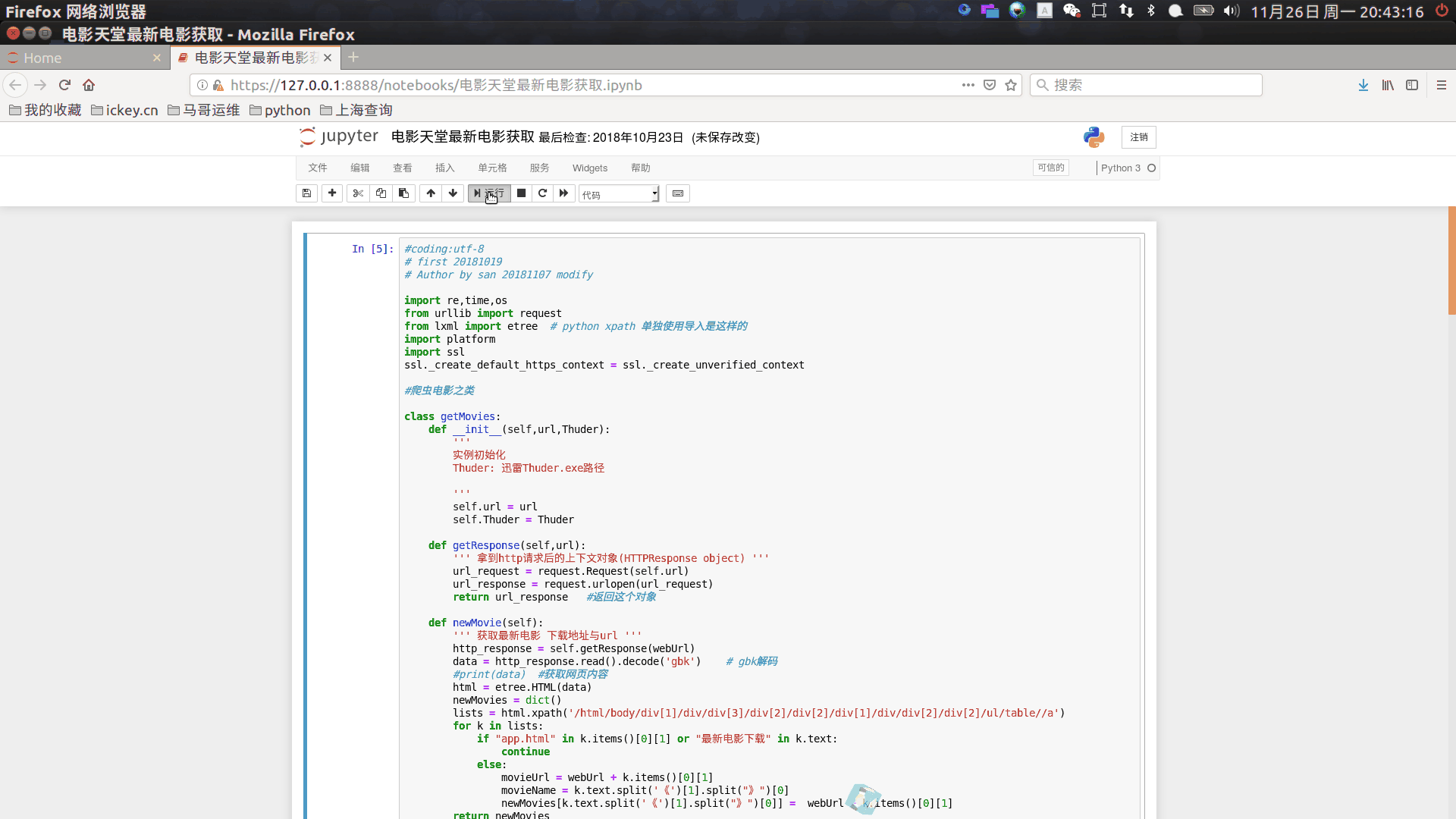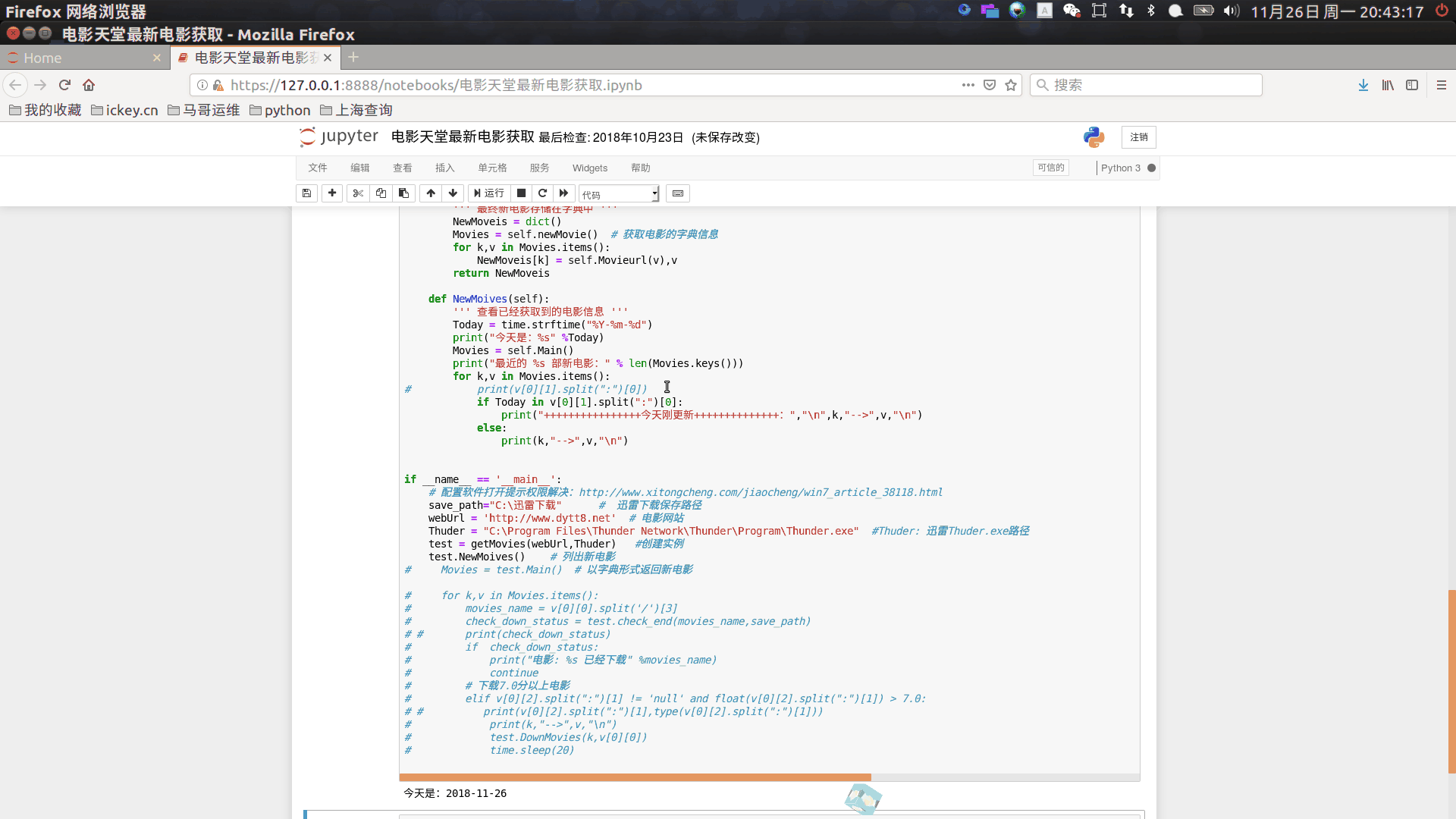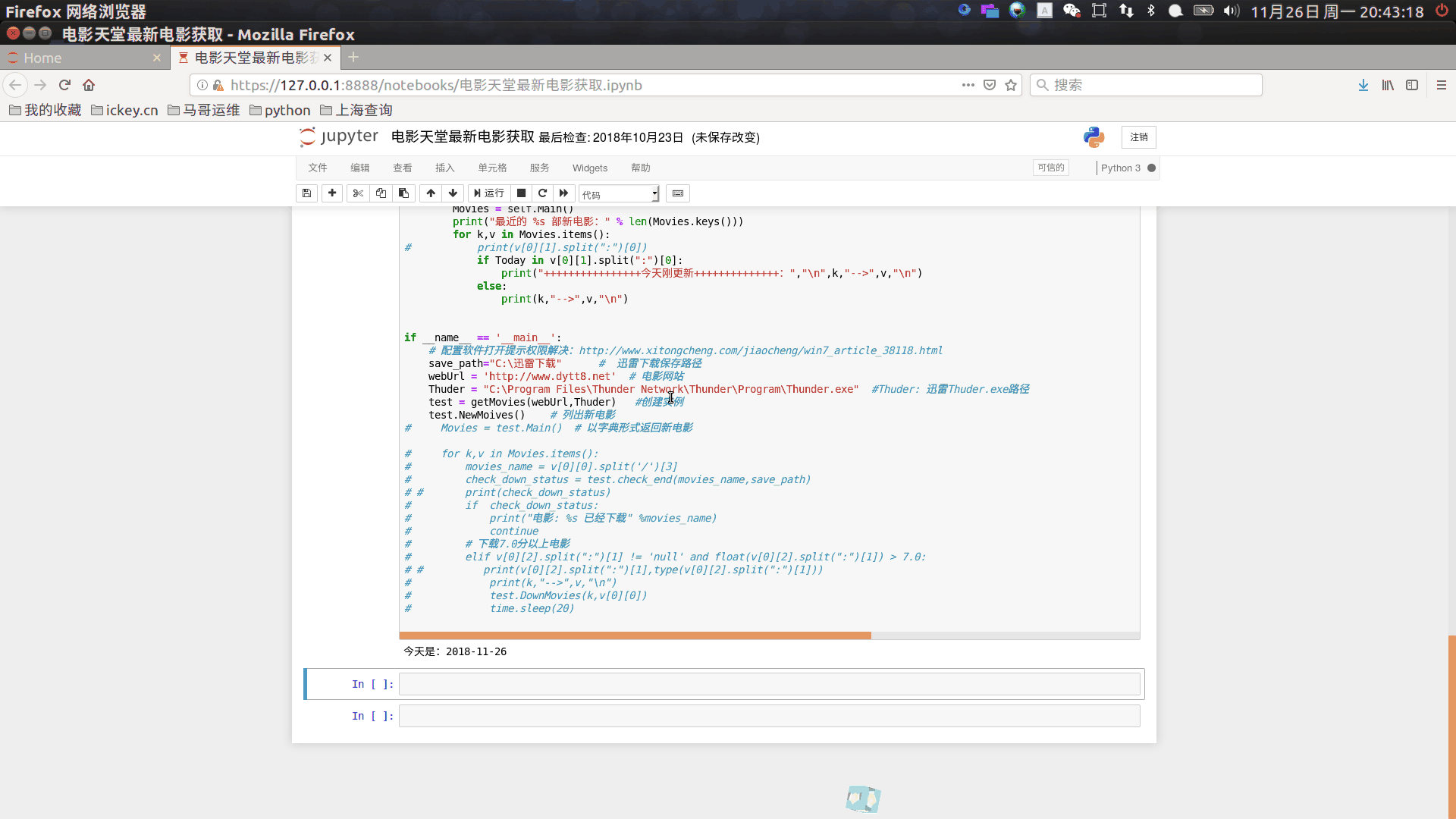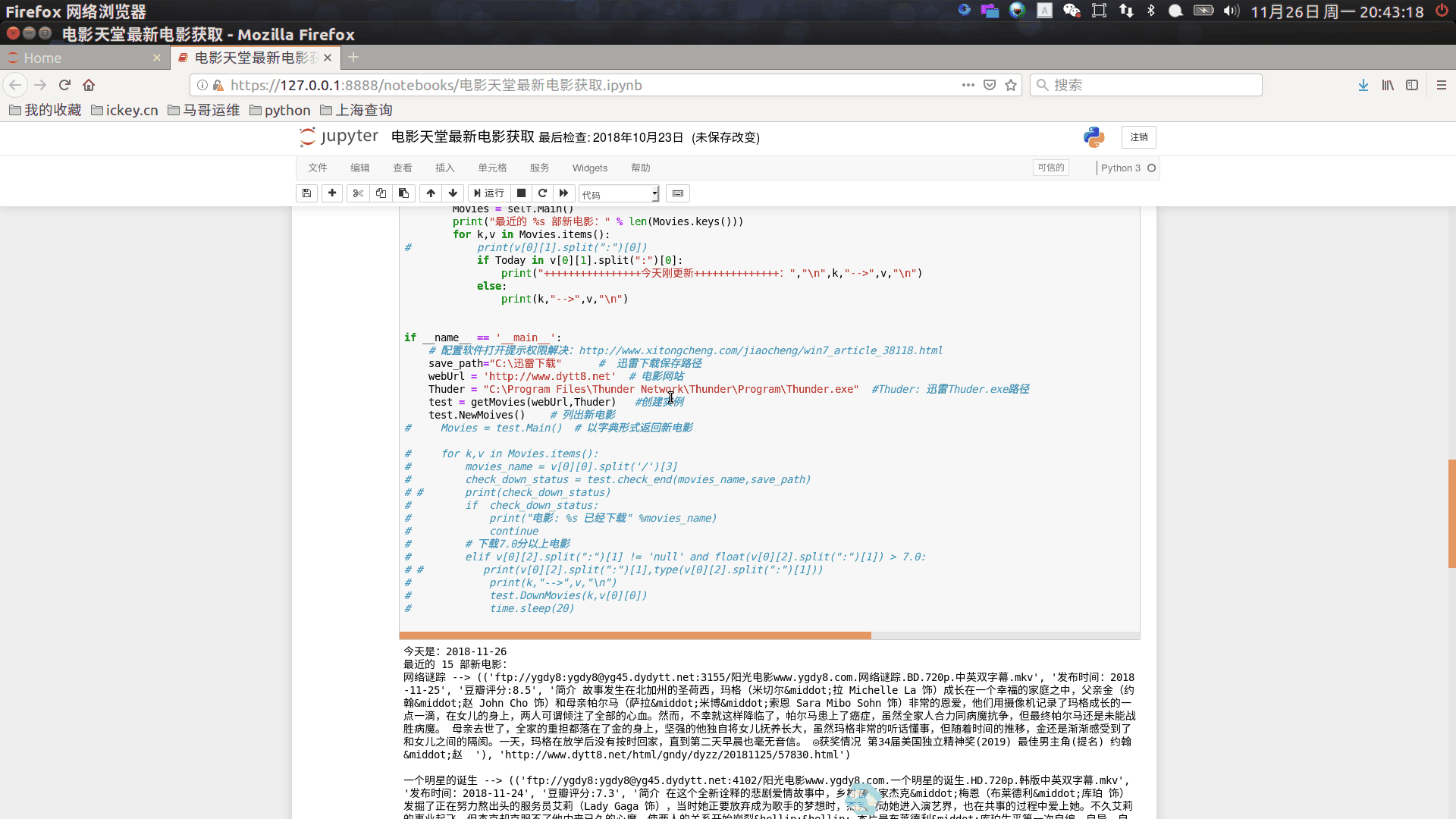
二、代码
废话不多说上代码吧~
# coding:utf-8# version 20181027 by sanimport re,time,osfrom urllib import requestfrom lxml import etree # python xpath 单独使用导入是这样的import platformimport sslssl._create_default_https_context = ssl._create_unverified_context # 取消全局证书#爬虫电影之类class getMovies: def __init__(self,url,Thuder): ''' 实例初始化 ''' self.url = url self.Thuder = Thuder def getResponse(self,url): url_request = request.Request(self.url) url_response = request.urlopen(url_request) return url_response #返回这个对象 def newMovie(self): ''' 获取最新电影 下载地址与url ''' http_response = self.getResponse(webUrl) #拿到http请求后的上下文对象(HTTPResponse object) data = http_response.read().decode('gbk') #print(data) #获取网页内容 html = etree.HTML(data) newMovies = dict() lists = html.xpath('/html/body/div[1]/div/div[3]/div[2]/div[2]/div[1]/div/div[2]/div[2]/ul/table//a') for k in lists: if "app.html" in k.items()[0][1] or "最新电影下载" in k.text: continue else: movieUrl = webUrl + k.items()[0][1] movieName = k.text.split('《')[1].split("》")[0] newMovies[k.text.split('《')[1].split("》")[0]] = movieUrl = webUrl + k.items()[0][1] return newMovies def Movieurl(self,url): ''' 获取评分和更新时间 ''' url_request = request.Request(url) movie_http_response = request.urlopen(url_request) data = movie_http_response.read().decode('gbk') if len(re.findall(r'豆瓣评分.+?.+users',data)): # 获取评分;没有评分的返回null pingf = re.findall(r'豆瓣评分.+?.+users',data)[0].split('/')[0].replace("\u3000",":") else: pingf = "豆瓣评分:null" desc = re.findall(r'简\s+介.*',data)[0].replace("\u3000","").replace('',"").split("src")[0].replace('&ldquo',"").replace('&rdquo',"").replace('![]() ",v,"\n") else: print("========================================") print(k,"-->",v,"\n")if __name__ == '__main__': # 以下依据您个人电影迅雷的相关信息填写即可 save_path="O:\迅雷下载" # 电影下载保存位置 (需要填写) Thuder = "O:\Program\Thunder.exe" #Thuder: 迅雷Thuder.exe路径 (需要填写) webUrl = 'http://www.dytt8.net' # 电影网站 test = getMovies(webUrl,Thuder) # 实例化 test.NewMoives() Movies = test.Main() for k,v in Movies.items(): movies_name = v[0][0].split('/')[3] socre = v[0][2].split(":")[1] check_down_status = test.check_end(movies_name,save_path)# print(check_down_status) if check_down_status: print("电影: %s 已经下载" %movies_name) continue elif socre == 'null': continue elif float(socre) > 7.0: print(movies_name,socre) test.DownMovies(k,v[0][0]) time.sleep(10)
",v,"\n") else: print("========================================") print(k,"-->",v,"\n")if __name__ == '__main__': # 以下依据您个人电影迅雷的相关信息填写即可 save_path="O:\迅雷下载" # 电影下载保存位置 (需要填写) Thuder = "O:\Program\Thunder.exe" #Thuder: 迅雷Thuder.exe路径 (需要填写) webUrl = 'http://www.dytt8.net' # 电影网站 test = getMovies(webUrl,Thuder) # 实例化 test.NewMoives() Movies = test.Main() for k,v in Movies.items(): movies_name = v[0][0].split('/')[3] socre = v[0][2].split(":")[1] check_down_status = test.check_end(movies_name,save_path)# print(check_down_status) if check_down_status: print("电影: %s 已经下载" %movies_name) continue elif socre == 'null': continue elif float(socre) > 7.0: print(movies_name,socre) test.DownMovies(k,v[0][0]) time.sleep(10) 注意:以上代码是针对windows平台下,迅雷版本为非极速版本,本次使用的是9.14 如图:
 另外需要勾选以下配置项,否则程序调用迅雷下载时会有提示框:
另外需要勾选以下配置项,否则程序调用迅雷下载时会有提示框:
程序运行效果如图:


再看下O盘 下载的目录:

至此自动获取最新电影并下载指定评分电影完成~ 再也不用担心选择困难了,下好看就行了~
补充说明:
这只是一个基本的获取并下载电影的程序,也可能扩充成下载好发邮件,或不想下载,定时运行,有新电影发邮件提示的功能~更功能自行发挥吧,如有那位大牛知道linux下自行下载的方法,欢迎留言交流,谢谢~如果觉得还可以,不要忘记点个赞哦~转载于:https://blog.51cto.com/dyc2005/2309658
你可能感兴趣的文章
微信小程序 js逻辑
查看>>
linux 安装 sftp
查看>>
openStack queens
查看>>
(转)EOSIO开发(四)- nodeos、keosd与cleos
查看>>
MVC5+EF6 入门完整教程八
查看>>
Java 设计模式专栏
查看>>
常用Mysql或者PostGresql或者Greenplum的语句总结。
查看>>
工控随笔_12_西门子_WinCC的VBS脚本_03_变量类型
查看>>
appium 报错
查看>>
phpquery中文手册
查看>>
使用ASP.NET Atlas SortBehavior实现客户端排序
查看>>
图像滤镜处理算法:灰度、黑白、底片、浮雕
查看>>
Office文档出错的几种原因与解决方法
查看>>
正则表达式 学习笔记1.1
查看>>
AssetBundle进阶内存优化(Unity 4.x)
查看>>
Ruby中写一个判断成绩分类的脚本
查看>>
《从零开始学Swift》学习笔记(Day 40)——析构函数
查看>>
Exchange2003-2010迁移系列之十,Exchange证书攻略
查看>>
extmail集群的邮件负载均衡方案 [lvs dns postfix]
查看>>
SCCM2012SP1---资产管理和远程管理
查看>>